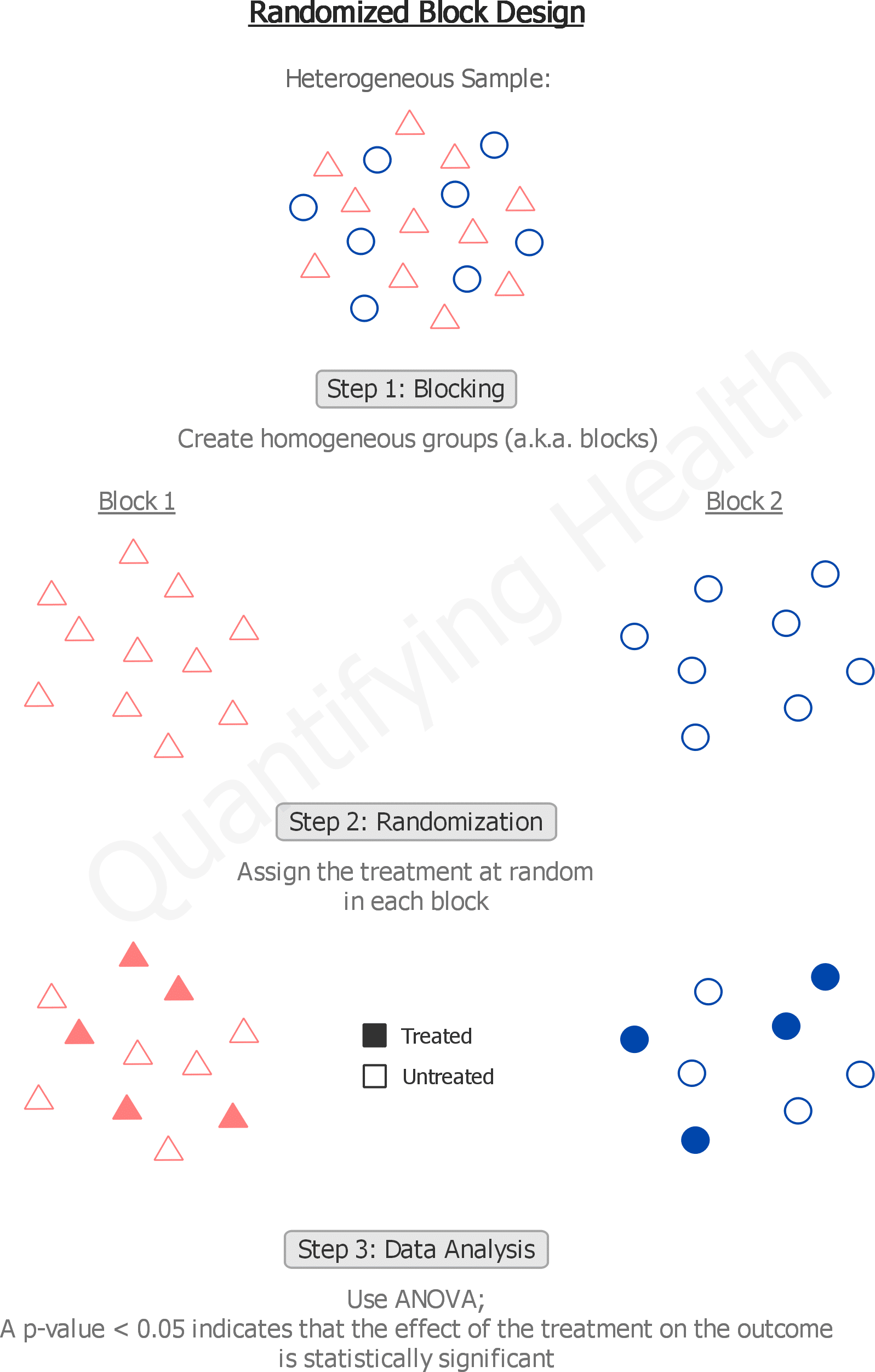
A randomized block design is a type of experiment where participants who share certain characteristics are grouped together to form blocks, and then the treatment (or intervention) gets randomly assigned within each block.
The objective of the randomized block design is to form groups where participants are similar, and therefore can be compared with each other.
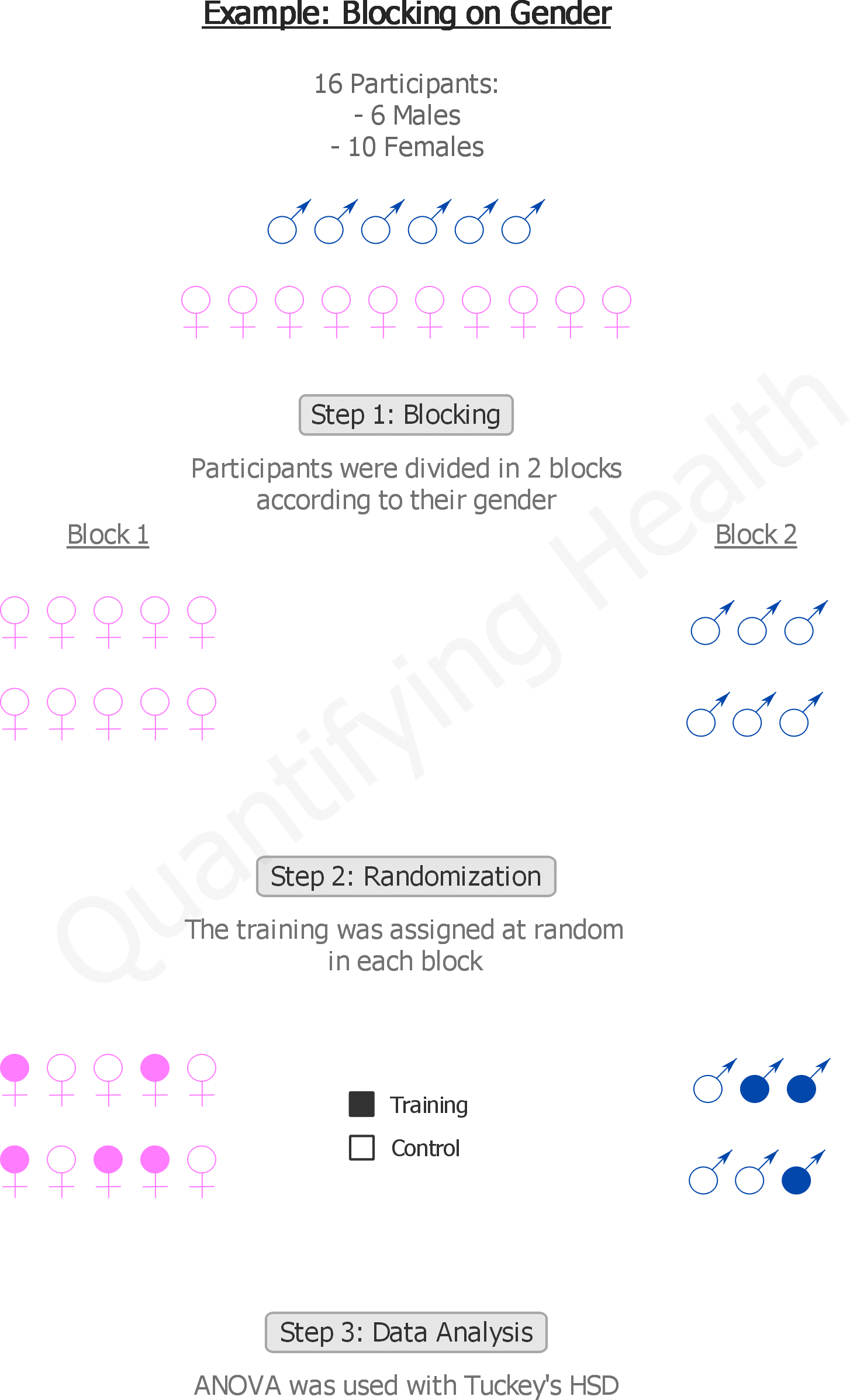
An Example: Blocking on gender
Santana-Sosa et al. set to study the effect of a 12-week physical training program on the ability to perform daily activities in Alzheimer’s disease patients.
And because physical capability differs substantially between males and females, the authors decided to block on gender.
Why gender?
Because gender satisfies the following 2 conditions:
- It will certainly affect the test measurements (i.e. the outcome)
- It is not an interesting variable in itself to be studied (as it is better to study variables that CAN be manipulated by patients in order to improve their physical ability)
Therefore, it would be very useful to block on gender in order to remove its effect as an alternative explanation of the outcome.
16 patients participated in the study: 10 females and 6 males.
The blocks were created as follows:
When to use a randomized block design?
Use a randomized block design if:
- An unwanted/uninteresting variable affects the outcome.
- This variable can be measured.
- Your sample size is not large enough for simple randomization to produce equal groups (see Randomized Block Design vs Completely Randomized Design).
What happens if you don’t block?
If you don’t block, all the variability associated with the blocks end up in the error term which makes it hard to detect an effect when in fact there is one.
So if you don’t block, you will reduce the statistical power of the study.
In other words, when the error term is inflated, the percentage of variability explained by the statistical model diminishes. Therefore, the model becomes a less accurate representation of reality.
BOTTOM LINE:
Blocking reduces the error term, making your statistical model more predictive and more generalizable.
Limitations of the randomized block design
Here are some of the limitations of the randomized block design and how to deal with them:
1. We cannot block on too many variables
As the number of blocking variables increases, the number of blocks created increases, approaching the sample size — i.e. the number of participants in each block would be very low, creating a problem for the randomized block design.
2. Difficulty in choosing the number of blocks
Since the number of blocks is the number of categories of the blocking variable, choosing a blocking variable that does not have too much or too few categories will be important because:
- If you used fewer blocks than you need: You may have a hard time maintaining homogeneity within each block.
- If you used more blocks than your sample size allows: You may end up with few participants in each block to be properly randomized to treatment options.
When in doubt, decide on the number of blocks based on previous literature.
3. Difficulty in detecting/measuring the blocking variable
We will divide this section into 3 categories [Source: Design and Analysis of Experiments]:
- When the blocking variable is known and controllable:
Solution: Use a randomized block design. - When the blocking variable is known but uncontrollable:
Solution: Try to adjust for it in the statistical analysis. - When the blocking variable is unknown:
Solution: Use simple randomization in the hope that it will produce equal and comparable study groups.
References
- Lewis-Beck M, Bryman A, Liao T. The SAGE Encyclopedia of Social Science Research Methods.; 2004. doi:10.4135/9781412950589
- Lawson J. Design and Analysis of Experiments with R. 1 edition. Chapman and Hall/CRC; 2014.
- Design of Experiments. Coursera. Accessed August 18, 2020.