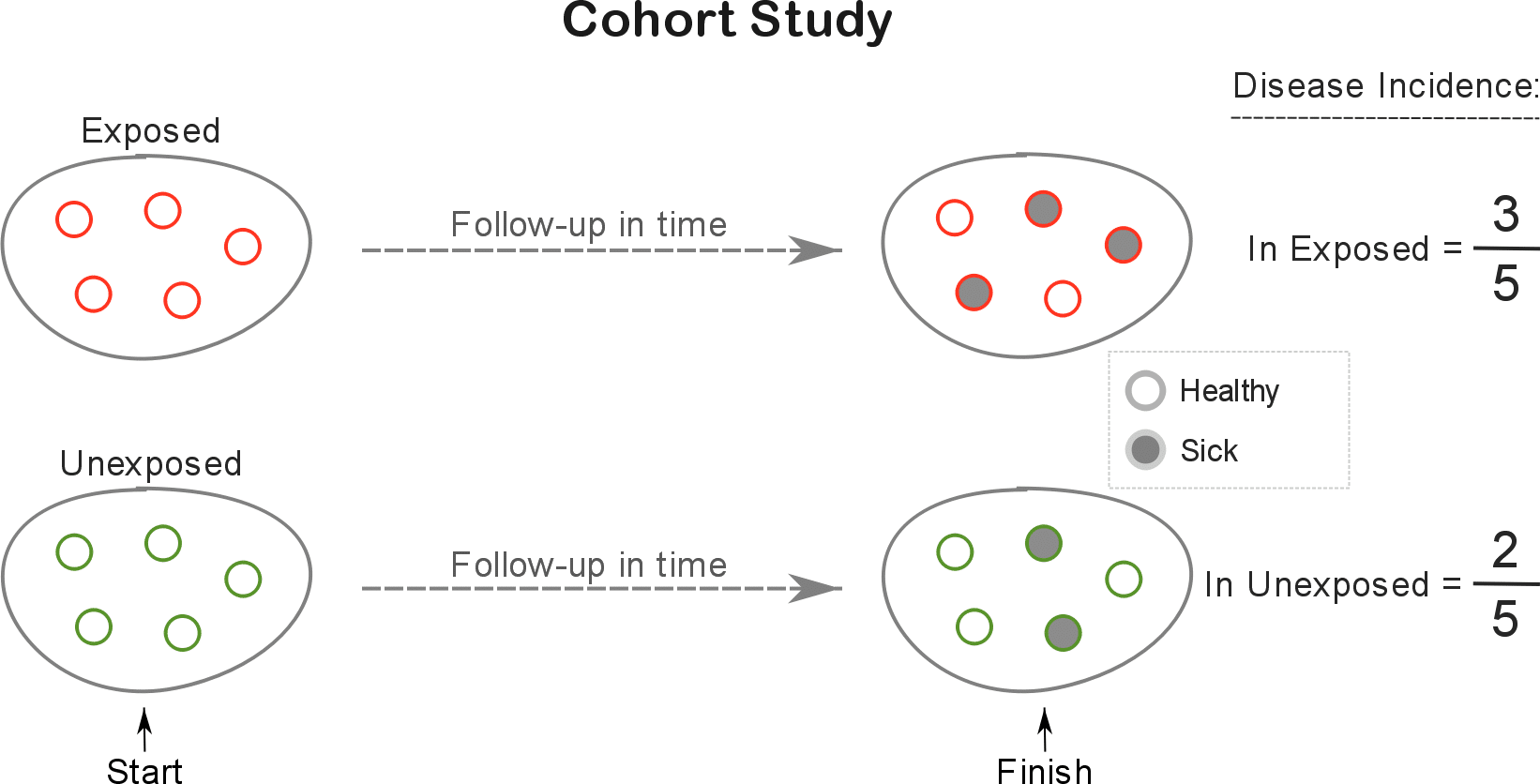
In a cohort study, the researcher selects a group of exposed and another group of unexposed individuals and follows them over time to determine whether or not a particular outcome of interest will occur.
The objective is to find out which group is more likely to develop the outcome (eg. disease) by comparing its incidence (i.e. the number of individuals who developed this disease) in both groups over that period of time.
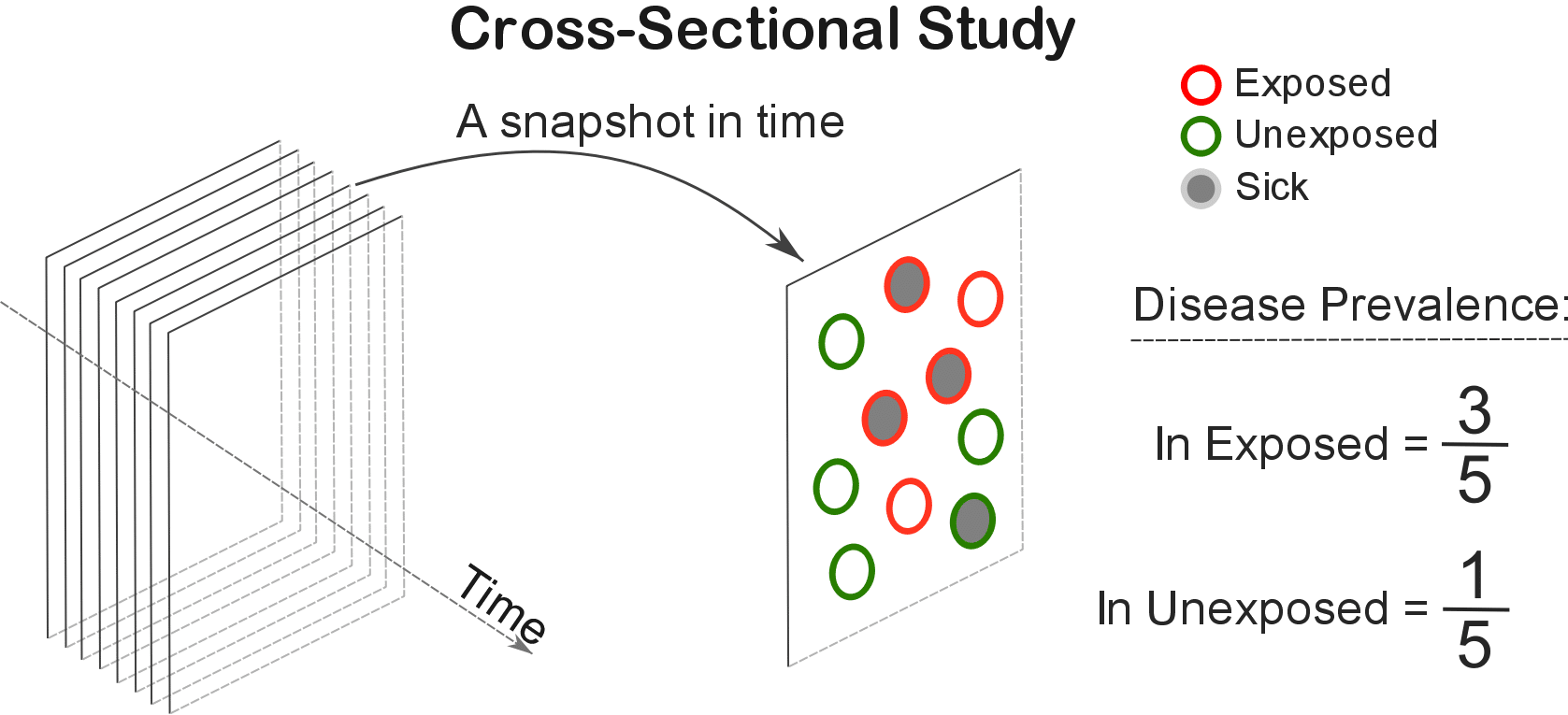
In a cross-sectional study, the researcher collects data simultaneously on both exposure and outcome at one given point in time.
The objective is to find out if the exposure is related to the outcome by comparing the prevalence of the outcome (i.e. the proportion of people who have the disease) in exposed and unexposed individuals.
Similarities between cohort and cross-sectional designs
1. Both are observational studies
In experiments (a.k.a. Randomized Controlled Trials), the investigator actively determines (in general via random allocation) who gets exposed to the risk factor (or treatment) and who doesn’t.
In observational studies, the investigator is an observer and does not intervene. So the participants are naturally divided into 2 groups: the exposed and the unexposed.
2. Both designs aim to study the association between an exposure and an outcome
So before conducting a cross-sectional or a cohort study, we need to have at least 1 hypothesis on which exposure or risk factor we think may cause the outcome.
We can of course examine multiple hypotheses by testing the association of more than 1 exposure with the outcome.
However, we should keep the number of statistical tests at minimum, as with multiple testing we will be at risk of p-hacking — in simple terms, by doing multiple tests, some associations will appear statistically significant just by chance.
3. Both are subject to information bias
Both cohort and cross-sectional studies are subject to bias in collection of information, errors in measurement of exposure and outcome, misclassification of participants, and bias in data analysis.
4. Both are subject to selection bias
People may refuse to participate in any type of study. The problem is when those who refuse to participate are not a random group people, but instead have higher or lower chance of being exposed (or having the disease) therefore biasing the study results.
5. Both are subject to confounding
Confounding happens when some variable or factor confuses the association between exposure and outcome, tricking us into believing, for example, that there is a statistically significant association between exposure and outcome, when, in reality there isn’t.
What this means is that, if we find an association between exposure and outcome in a cohort or a cross-sectional study, we cannot be 100% sure that it is causal in nature.
Differences between cohort and cross-sectional designs
Where a cohort design is better
1. A cohort is better for assessing causality
When trying to determine whether an exposure causes a particular outcome, it is very important that at least the exposure precedes the outcome.
In a cohort design, because we start with exposed and unexposed participants and follow them in time, we can be sure that the exposure occurred before the disease.
In a cross-sectional study, the exposure and the outcome are measured at the same time, so it is harder to determine which comes first.
2. Unlike a cross-sectional study, a cohort is not prone to survival bias
Suppose we have a risk factor that shortens the life of people who are exposed to it.
So if take a snapshot of people who are alive at a certain point in time (i.e. conduct a cross-sectional study), then we are by definition measuring the survivors excluding those who died of the disease caused by the exposure.
This will bias the study toward falsely concluding that the exposure is not related to the disease.
Where a cross-sectional design is better
1. In general, a cross-sectional study is less expensive and less time-consuming
In a cohort study we need to wait for the outcome to occur. In case of rare outcomes, the follow-up period may be very long (sometimes we will be waiting years for the outcome to develop in enough numbers so that the exposed and unexposed groups can be compared).
A cross-sectional design will be, in general, cheaper and faster to execute.
Here’s an example of how this translates in practice:
Suppose we have a new hypothesis about a causative association between 2 variables. A smart decision might be to start with a cross-sectional design (as it is faster and cheaper), then if the results are positive, replicate the results using a cohort or a randomized controlled trial if possible.
Because it is fast and cheap, a cross-sectional study is useful for assessing the disease burden in society — it is good for examining a change in the prevalence of a disease or an exposure, for instance, for studying the trend in cancer, heart disease, etc.
2. In a cross-sectional study you won’t have to deal with participants follow-up
A cohort design requires following people over a period of time, so participants may be lost to follow-up. This may happen for a variety of reasons, but the problem occurs when loss to follow-up does not happen at random.
For instance, if participants who are more (or less) likely than others to develop the outcome are lost to follow-up the study will be biased.
A cross-sectional study does not suffer from such bias as it does not follow participants in time.